Managing Data
Deployments of ClickHouse for Observability invariably involve large datasets, which need to be managed. ClickHouse offers a number of features to assist with data management.
Partitions
Partitioning in ClickHouse allows data to be logically separated on disk according to a column or SQL expression. By separating data logically, each partition can be operated on independently e.g. deleted. This allows users to move partitions, and thus subsets, between storage tiers efficiently on time or expire data/efficiently delete from a cluster.
Partitioning is specified on a table when it is initially defined via the PARTITION BY clause. This clause can contain a SQL expression on any column/s, the results of which will define which partition a row is sent to.
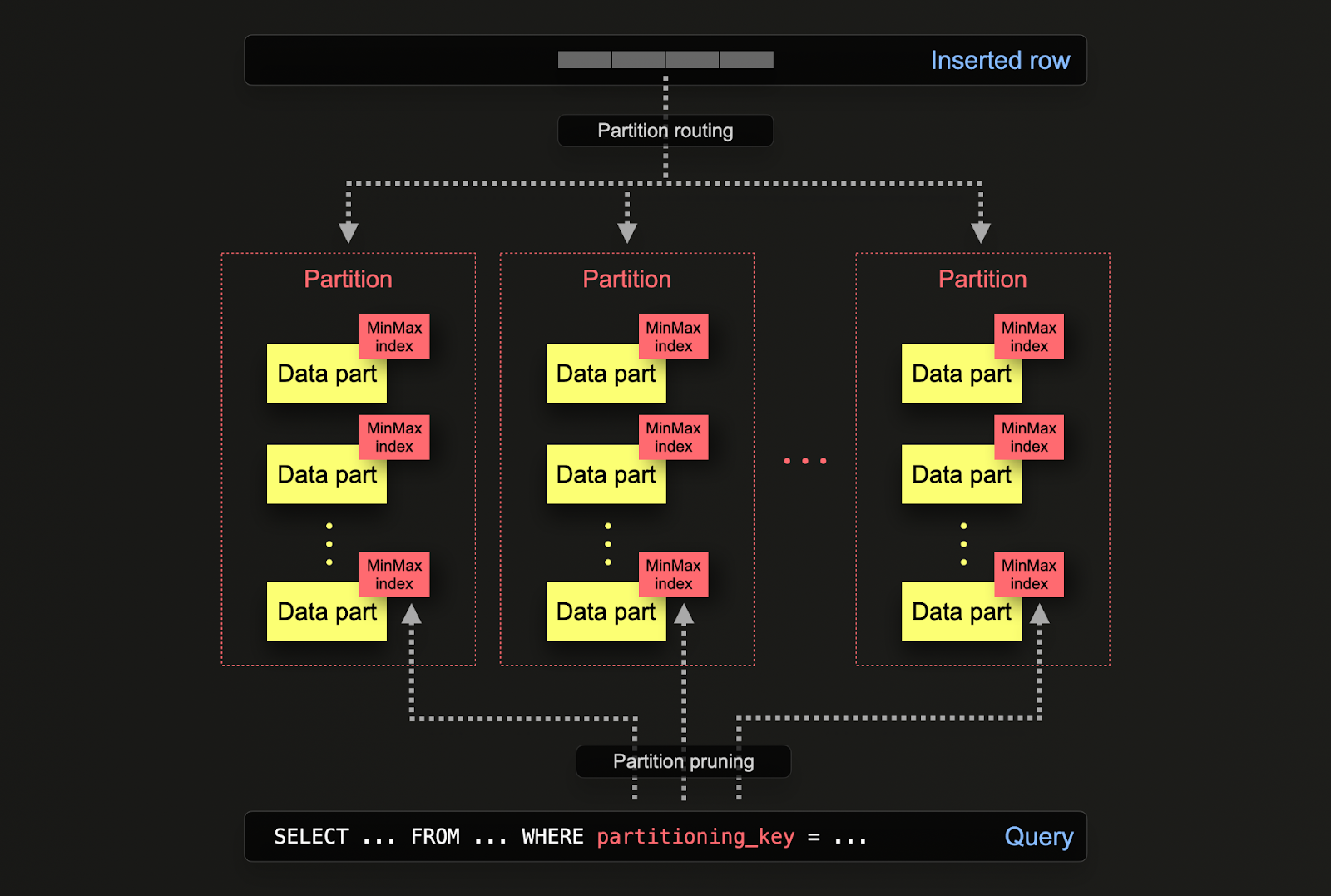
The data parts are logically associated (via a common folder name prefix) with each partition on the disk and can be queried in isolation. For the example below, default otel_logs schema partitions by day using the expression toDate(Timestamp). As rows are inserted into ClickHouse, this expression will be evaluated against each row and routed to the resulting partition if it exists (if the row is the first for a day, the partition will be created).
CREATE TABLE default.otel_logs
(
...
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)
A number of operations can be performed on partitions, including backups, column manipulations, mutations altering/deleting data by row) and index clearing (e.g. secondary indices).
As an example, suppose our otel_logs table is partitioned by day. If populated with the structured log dataset, this will contain several days of data:
SELECT Timestamp::Date AS day,
count() AS c
FROM otel_logs
GROUP BY day
ORDER BY c DESC
┌────────day─┬───────c─┐
│ 2019-01-22 │ 2333977 │
│ 2019-01-23 │ 2326694 │
│ 2019-01-26 │ 1986456 │
│ 2019-01-24 │ 1896255 │
│ 2019-01-25 │ 1821770 │
└────────────┴─────────┘
5 rows in set. Elapsed: 0.058 sec. Processed 10.37 million rows, 82.92 MB (177.96 million rows/s., 1.42 GB/s.)
Peak memory usage: 4.41 MiB.
Current partitions can be found using a simple system table query:
SELECT DISTINCT partition
FROM system.parts
WHERE `table` = 'otel_logs'
┌─partition──┐
│ 2019-01-22 │
│ 2019-01-23 │
│ 2019-01-24 │
│ 2019-01-25 │
│ 2019-01-26 │
└────────────┘
5 rows in set. Elapsed: 0.005 sec.
We may have another table, otel_logs_archive, which we use to store older data. Data can be moved to this table efficiently by partition (this is just a metadata change).
CREATE TABLE otel_logs_archive AS otel_logs
--move data to archive table
ALTER TABLE otel_logs
(MOVE PARTITION tuple('2019-01-26') TO TABLE otel_logs_archive
--confirm data has been moved
SELECT
Timestamp::Date AS day,
count() AS c
FROM otel_logs
GROUP BY day
ORDER BY c DESC
┌────────day─┬───────c─┐
│ 2019-01-22 │ 2333977 │
│ 2019-01-23 │ 2326694 │
│ 2019-01-24 │ 1896255 │
│ 2019-01-25 │ 1821770 │
└────────────┴─────────┘
4 rows in set. Elapsed: 0.051 sec. Processed 8.38 million rows, 67.03 MB (163.52 million rows/s., 1.31 GB/s.)
Peak memory usage: 4.40 MiB.
SELECT Timestamp::Date AS day,
count() AS c
FROM otel_logs_archive
GROUP BY day
ORDER BY c DESC
┌────────day─┬───────c─┐
│ 2019-01-26 │ 1986456 │
└────────────┴─────────┘
1 row in set. Elapsed: 0.024 sec. Processed 1.99 million rows, 15.89 MB (83.86 million rows/s., 670.87 MB/s.)
Peak memory usage: 4.99 MiB.
This is in contrast to other techniques, which would require the use of an INSERT INTO SELECT and a rewrite of the data into the new target table.
Moving partitions between tables requires several conditions to be met, not least tables must have the same structure, partition key, primary key and indices/projections. Detailed notes on how to specify partitions in ALTER DDL can be found here.
Furthermore, data can be efficiently deleted by partition. This is far more resource-efficient than alternative techniques (mutations or lightweight deletes) and should be preferred.
ALTER TABLE otel_logs
(DROP PARTITION tuple('2019-01-25'))
SELECT
Timestamp::Date AS day,
count() AS c
FROM otel_logs
GROUP BY day
ORDER BY c DESC
┌────────day─┬───────c─┐
│ 2019-01-22 │ 4667954 │
│ 2019-01-23 │ 4653388 │
│ 2019-01-24 │ 3792510 │
└────────────┴─────────┘
This feature is exploited by TTL when the setting ttl_only_drop_parts=1 is used. See Data management with TTL for further details.
Applications
The above illustrates how data can be efficiently moved and manipulated by partition. In reality, users will likely most frequently exploit partition operations in Observability use cases for two scenarios:
- Tiered architectures - Moving data between storage tiers (see Storage tiers), thus allowing hot-cold architectures to be constructed.
- Efficient deletion - when data has reached a specified TTL (see Data management with TTL)
We explore both of these in detail below.
Query Performance
While partitions can assist with query performance, this depends heavily on the access patterns. If queries target only a few partitions (ideally one), performance can potentially improve. This is only typically useful if the partitioning key is not in the primary key and you are filtering by it. However, queries which need to cover many partitions may perform worse than if no partitioning is used (as there may possibly be more parts). The benefit of targeting a single partition will be even less pronounced to non-existent if the partitioning key is already an early entry in the primary key. Partitioning can also be used to optimize GROUP BY queries if values in each partition are unique. However, in general, users should ensure the primary key is optimized and only consider partitioning as a query optimization technique in exceptional cases where access patterns access a specific predictable subset of the day, e.g., partitioning by day, with most queries in the last day. See here for an example of this behavior.
Data management with TTL (Time-to-live)
Time-to-Live (TTL) is a crucial feature in observability solutions powered by ClickHouse for efficient data retention and management, especially given vast amounts of data are continuously generated. Implementing TTL in ClickHouse allows for automatic expiration and deletion of older data, ensuring that the storage is optimally used and performance is maintained without manual intervention. This capability is essential for keeping the database lean, reducing storage costs, and ensuring that queries remain fast and efficient by focusing on the most relevant and recent data. Moreover, it helps in compliance with data retention policies by systematically managing data lifecycles, thus enhancing the overall sustainability and scalability of the observability solution.
TTL can be specified at either the table or column level in ClickHouse.
Table level TTL
The default schema for both logs and traces includes a TTL to expire data after a specified period. This is specified in the ClickHouse exporter under a ttl key e.g.
exporters:
clickhouse:
endpoint: tcp://localhost:9000?dial_timeout=10s&compress=lz4&async_insert=1
ttl: 72h
This syntax currently supports Golang Duration syntax. We recommend users use h and ensure this aligns with the partitioning period. For example, if you partition by day, ensure it is a multiple of days, e.g., 24h, 48h, 72h. This will automatically ensure a TTL clause is added to the table e.g. if ttl: 96h.
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SpanName, toUnixTimestamp(Timestamp), TraceId)
TTL toDateTime(Timestamp) + toIntervalDay(4)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1
By default, data with an expired TTL is removed when ClickHouse merges data parts. When ClickHouse detects that data is expired, it performs an off-schedule merge.
TTLs are not applied immediately but rather on a schedule, as noted above. The MergeTree table setting merge_with_ttl_timeout sets the minimum delay in seconds before repeating a merge with delete TTL. The default value is 14400 seconds (4 hours). But that is just the minimum delay, it can take longer until a TTL merge is triggered. If the value is too low, it will perform many off-schedule merges that may consume a lot of resources. A TTL expiration can be forced using the command ALTER TABLE my_table MATERIALIZE TTL.
Important: We recommend using the setting ttl_only_drop_parts=1 (applied by the default schema). When this setting is enabled, ClickHouse drops a whole part when all rows in it are expired. Dropping whole parts instead of partial cleaning TTL-d rows (achieved through resource-intensive mutations when ttl_only_drop_parts=0) allows having shorter merge_with_ttl_timeout times and lower impact on system performance. If data is partitioned by the same unit at which you perform TTL expiration e.g. day, parts will naturally only contain data from the defined interval. This will ensure ttl_only_drop_parts=1 can be efficiently applied.
Column level TTL
The above example expires data at a table level. Users can also expire data at a column level. As data ages, this can be used to drop columns whose value in investigations does not justify their resource overhead to retain. For example, we recommend retaining the Body column in case new dynamic metadata is added that has not been extracted at insert time, e.g., a new Kubernetes label. After a period e.g. 1 month, it might be obvious that this additional metadata is not useful - thus limiting the value in retaining the Body column.
Below, we show how the Body column can be dropped after 30 days.
CREATE TABLE otel_logs_v2
(
`Body` String TTL Timestamp + INTERVAL 30 DAY,
`Timestamp` DateTime,
...
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
Specifying a column level TTL requires users to specify their own schema. This cannot be specified in the OTel collector.
Recompressing data
While we typically recommend ZSTD(1) for observability datasets, users can experiment with different compression algorithms or higher levels of compression e.g. ZSTD(3). As well as being able to specify this on schema creation, the compression can be configured to change after a set period. This may be appropriate if a codec or compression algorithm improves compression but causes poorer query performance. This tradeoff might be acceptable on older data, which is queried less frequently, but not for recent data, which is subject to more frequent use in investigations.
An example of this is shown below, where we compress the data using ZSTD(3) after 4 days instead of deleting it.
CREATE TABLE default.otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
TTL Timestamp + INTERVAL 4 DAY RECOMPRESS CODEC(ZSTD(3))
We recommend users always evaluate both the insert and query performance impact of different compression levels and algorithms. For example, delta codecs can be helpful in the compression of timestamps. However, if these are part of the primary key then filtering performance can suffer.
Further details and examples on configuring TTL's can be found here. Examples such as how TTLs can be added and modified for tables and columns, can be found here. For how TTLs enable storage hierarchies such as hot-warm architectures, see Storage tiers.
Storage tiers
In ClickHouse, users may create storage tiers on different disks, e.g. hot/recent data on SSD and older data backed by S3. This architecture allows less expensive storage to be used for older data, which has higher query SLAs due to its infrequent use in investigations.
ClickHouse Cloud uses a single copy of the data that is backed on S3, with SSD-backed node caches. Storage tiers in ClickHouse Cloud, therefore, are not required.
The creation of storage tiers requires users to create disks, which are then used to formulate storage policies, with volumes that can be specified during table creation. Data can be automatically moved between disks based on fill rates, part sizes, and volume priorities. Further details can be found here.
While data can be manually moved between disks using the ALTER TABLE MOVE PARTITION command, the movement of data between volumes can also be controlled using TTLs. A full example can be found here.
Managing schema changes
Log and trace schemas will invariably change over the lifetime of a system e.g. as users monitor new systems which have different metadata or pod labels. By producing data using the OTel schema, and capturing the original event data in structured format, ClickHouse schemas will be robust to these changes. However, as new metadata becomes available and query access patterns change, users will want to update schemas to reflect these developments.
In order to avoid downtime during schema changes, users have several options, which we present below.
Use default values
Columns can be added to the schema using DEFAULT values. The specified default will be used if it is not specified during the INSERT.
Schema changes can be made prior to modifying any materialized view transformation logic or OTel collector configuration, which causes these new columns to be sent.
Once the schema has been changed, users can reconfigure OTeL collectors. Assuming users are using the recommended process outlined in "Extracting structure with SQL", where OTeL collectors send their data to a Null table engine with a materialized view responsible for extracting the target schema and sending the results to a target table for storage, the view can be modified using the ALTER TABLE ... MODIFY QUERY syntax. Suppose we have the target table below with its corresponding materialized view (similar to that used in "Extracting structure with SQL") to extract the target schema from the OTel structured logs:
CREATE TABLE default.otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
CREATE MATERIALIZED VIEW otel_logs_mv TO otel_logs_v2 AS
SELECT
Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
LogAttributes['status']::UInt16 AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddress,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
Suppose we wish to extract a new column Size from the LogAttributes. We can add this to our schema with an ALTER TABLE, specifying the default value:
ALTER TABLE otel_logs_v2
(ADD COLUMN `Size` UInt64 DEFAULT JSONExtractUInt(Body, 'size'))
In the above example, we specify the default as the size key in LogAttributes (this will be 0 if it doesn't exist). This means queries that access this column for rows that do not have the value inserted must access the Map and will, therefore, be slower. We could easily also specify this as a constant, e.g. 0, reducing the cost of subsequent queries against rows that do not have the value. Querying this table shows the value is populated as expected from the Map:
SELECT Size
FROM otel_logs_v2
LIMIT 5
┌──Size─┐
│ 30577 │
│ 5667 │
│ 5379 │
│ 1696 │
│ 41483 │
└───────┘
5 rows in set. Elapsed: 0.012 sec.
To ensure this value is inserted for all future data, we can modify our materialized view using the ALTER TABLE syntax as shown below:
ALTER TABLE otel_logs_mv
MODIFY QUERY
SELECT
Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
LogAttributes['status']::UInt16 AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['size'] AS Size,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddress,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
Subsequent rows will have a Size column populated at insert time.
Create new tables
As an alternative to the above process, users can simply create a new target table with the new schema. Any materialized views can then be modified to use the new table using the above ALTER TABLE MODIFY QUERY. With this approach, users can version their tables e.g. otel_logs_v3.
This approach leaves the users with multiple tables to query. To query across tables, users can use the merge function which accepts wildcard patterns for the table name. We demonstrate this below by querying a v2 and v3 of the otel_logs table:
SELECT Status, count() AS c
FROM merge('otel_logs_v[2|3]')
GROUP BY Status
ORDER BY c DESC
LIMIT 5
┌─Status─┬────────c─┐
│ 200 │ 38319300 │
│ 304 │ 1360912 │
│ 302 │ 799340 │
│ 404 │ 420044 │
│ 301 │ 270212 │
└────────┴──────────┘
5 rows in set. Elapsed: 0.137 sec. Processed 41.46 million rows, 82.92 MB (302.43 million rows/s., 604.85 MB/s.)
Should users wish to avoid using the merge function and expose a table to end users that combines multiple tables, the Merge table engine can be used. We demonstrate this below:
CREATE TABLE otel_logs_merged
ENGINE = Merge('default', 'otel_logs_v[2|3]')
SELECT Status, count() AS c
FROM otel_logs_merged
GROUP BY Status
ORDER BY c DESC
LIMIT 5
┌─Status─┬────────c─┐
│ 200 │ 38319300 │
│ 304 │ 1360912 │
│ 302 │ 799340 │
│ 404 │ 420044 │
│ 301 │ 270212 │
└────────┴──────────┘
5 rows in set. Elapsed: 0.073 sec. Processed 41.46 million rows, 82.92 MB (565.43 million rows/s., 1.13 GB/s.)
This can be updated whenever a new table is added using the EXCHANGE table syntax. For example, to add a v4 table we can create a new table and exchange this atomically with the previous version.
CREATE TABLE otel_logs_merged_temp
ENGINE = Merge('default', 'otel_logs_v[2|3|4]')
EXCHANGE TABLE otel_logs_merged_temp AND otel_logs_merged
SELECT Status, count() AS c
FROM otel_logs_merged
GROUP BY Status
ORDER BY c DESC
LIMIT 5
┌─Status─┬────────c─┐
│ 200 │ 39259996 │
│ 304 │ 1378564 │
│ 302 │ 820118 │
│ 404 │ 429220 │
│ 301 │ 276960 │
└────────┴──────────┘
5 rows in set. Elapsed: 0.068 sec. Processed 42.46 million rows, 84.92 MB (620.45 million rows/s., 1.24 GB/s.)